One of my favourite blog posts in recent times is The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay Kreps. That post comprehensively describes how abstracting all the data produced by LinkedIn’s various components into a single log pipeline greatly simplified their architecture and enabled advanced data-driven applications. Among the various technical details there are some beautifully-articulated business insights. My favourite one defines data’s hierarchy of needs:
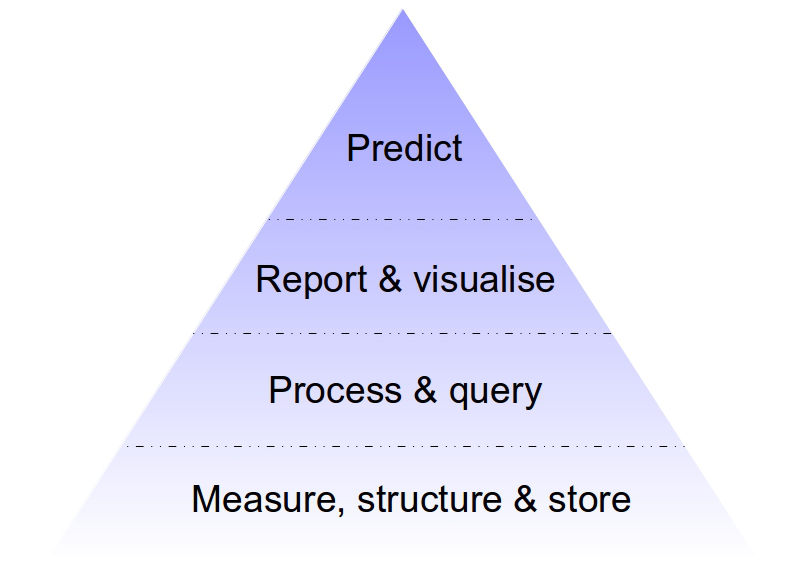
Effective use of data follows a kind of Maslow’s hierarchy of needs. The base of the pyramid involves capturing all the relevant data, being able to put it together in an applicable processing environment (be that a fancy real-time query system or just text files and python scripts). This data needs to be modeled in a uniform way to make it easy to read and process. Once these basic needs of capturing data in a uniform way are taken care of it is reasonable to work on infrastructure to process this data in various ways—MapReduce, real-time query systems, etc.
It’s worth noting the obvious: without a reliable and complete data flow, a Hadoop cluster is little more than a very expensive and difficult to assemble space heater. Once data and processing are available, one can move concern on to more refined problems of good data models and consistent well understood semantics. Finally, concentration can shift to more sophisticated processing—better visualization, reporting, and algorithmic processing and prediction.
In my experience, most organizations have huge holes in the base of this pyramid—they lack reliable complete data flow—but want to jump directly to advanced data modeling techniques. This is completely backwards. [emphasis mine]
Visually, it looks something like this:

In addition, before starting to build a data pipeline, one needs to ensure that the tracked system works as expected. For example, a buggy website is likely to produce weird metrics, which in turn would make the data processing, reporting and predictions unreliable. I completely agree with Jay’s point about needing to get the basis of the pyramid right before setting out to do “something with data” (which seems to be the desire of every company nowadays).
The general point is that it’s important to have realistic expectations about what can be obtained by data-driven algorithms and insights. These can only be as good as the underlying data, with the results always depending to a large degree on having a solid infrastructure. Not everything has to be perfect from the start (most things never will be), but some degree of robustness is required to avoid spending too many resources on things that would never work. Trying to apply the latest predictive models without a reliable data infrastructure is like driving a fancy car on broken roads – you’re unlikely to get very far.
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.