
I’ve been meaning to get into deep learning for the last few years. Now, the stars having finally aligned and I have the time and motivation to work on a small project that will hopefully improve my understanding of the field. This is the first in a series of posts that will document my progress on this project.
As mentioned in a previous post on getting started as a data scientist, I believe that the best way of becoming proficient at solving data science problems is by getting your hands dirty. Despite being familiar with high-level terminology and having some understanding of how it all works, I don’t have any practical experience applying deep learning. The purpose of this project is to fix this experience gap by working on a real problem.
The problem: Inferring genre from album covers
Deep learning has been very successful at image classification. Therefore, it makes sense to work on an image classification problem for this project. Rather than using an existing dataset, I decided to make things a bit more interesting by building my own dataset. Over the last year, I’ve been running BCRecommender – a recommendation system for Bandcamp music. I’ve noticed that album covers vary by genre, though it’s hard to quantify exactly how they vary. So the question I’ll be trying to answer with this project is how accurately can genre be inferred from Bandcamp album covers?
As the goal of this project is to learn about deep learning rather than make a novel contribution, I didn’t do a comprehensive search to see whether this problem has been addressed before. However, I did find a recent post by Alexandre Passant that describes his use of Clarifai’s API to tag the content of Spotify album covers (identifying elements such as men, night, dark, etc.), and then using these tags to infer the album’s genre. Another related project is Karayev et al.’s Recognizing image style paper, in which the authors classified datasets of images from Flickr and Wikipedia by style and art genre, respectively. In all these cases, the results are pretty good, supporting my intuition that the genre inference task is feasible.
Data collection & splits
As I’ve already been crawling Bandcamp data for BCRecommender, creating the dataset was relatively straightforward. Currently, I have data on about 1.8 million tracks and albums. Bandcamp artists assign multiple tags to each release. To create the dataset, I selected 10 of the top tags: ambient, dubstep, folk, hiphop_rap, jazz, metal, pop, punk, rock, and soul. Then, I randomly selected 10,000 album covers that have exactly one of those tags, with 1,000 albums for each tag/genre. Each cover image size is 350×350. The following image shows a sample of the dataset.
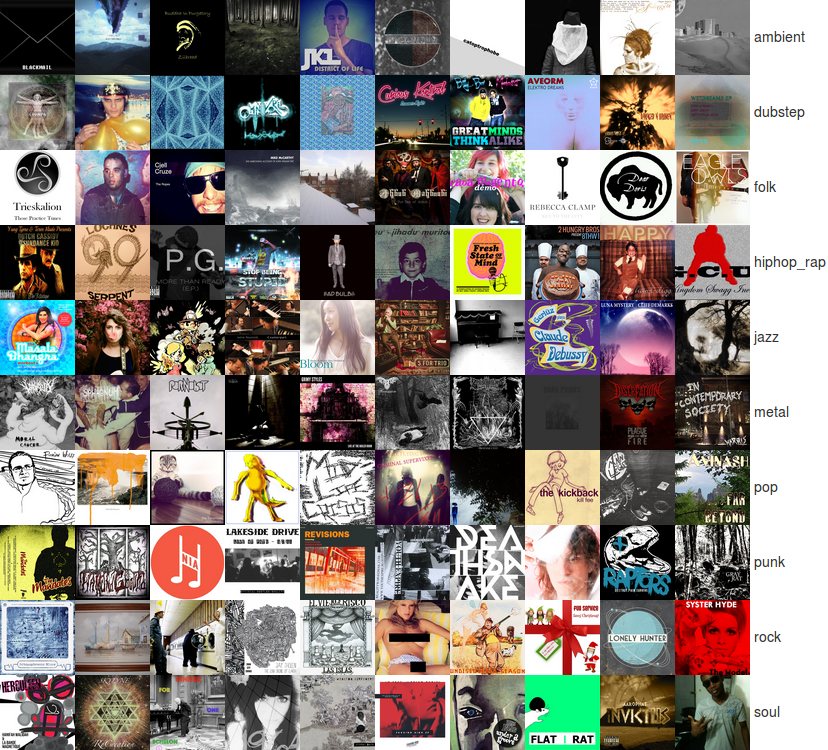
It is apparent that some genres can be inferred more easily than others, especially when browsing through the full dataset. For example, metal albums tend to be pretty distinct. I doubt that predictive accuracy would be very high, but I think that it can definitely be much better than the random baseline of 10%.
For training, validation and testing I decided to use a static stratified 80%/10%/10% split of the dataset. It quickly became apparently that the full dataset is too big for development purposes, making it hard to quickly test code on my local machine. To address this, I created a local development dataset, using an 80%/10%/10% split of 1,000 images from the full training subset.
The code for downloading the dataset and creating the splits is available from the project repository on GitHub. This repository will include all the code for the project as it evolves. I will try to keep it well-documented enough to be useful for others, though it assumes some familiarity with Python. If you experience any issues running the code or find any bugs, please let me know.
Getting started
One of the things that has stopped me from playing with deep learning in the past is the feeling that there is a bit of a steep learning curve around the tools and methods. A lot of the deep learning libraries out there don’t seem as mature as general machine learning libraries, such as scikit-learn. There are also many more parameters to play with when building deep neural networks than when using linear models or algorithms such as random forests. Further, to enable any kind of meaningful experimentation, using a GPU is essential.
Fortunately, the tools and documentation have matured a lot in recent years. Motivated by Daniel Nouri’s excellent tutorial on detecting facial keypoints with convolutional neural nets, I decided to use the Lasagne package as my starting point. My plan was simple: Convert the MNIST example code to work on my dataset locally, setup an AWS machine with a GPU for full-scale experiments, and then play with various network architectures and techniques to improve accuracy and gain a deeper understanding of deep learning.
Initial environment setup
While Lasagne’s MNIST example code is pretty clear – especially once you get your head around the way Theano works – it doesn’t really lend itself to easy experimentation. I addressed this by refactoring the code in several iterations, until I got to the current state, where there’s a simple command-line interface that allows me to experiment with different datasets and architectures. This will probably change and become more complex as I start doing more sophisticated things.
To enable rapid experimentation, I had to set up an AWS machine with a GPU (g2.2xlarge instance). I wrote some simple deployment code using Fabric, which allows me to setup a machine from scratch, install all the requirements, package the project, and copy it to the remote machine.
Getting the code running on the CPU was trivial, but I hit several issues when running on the GPU. First, the vanilla Ubuntu 14.04 server I used didn’t come with CUDA installed. After trying and failing to get it working by following some tutorials, I ended up going down the easier path of using the AMI supplied by Caffe. This AMI also has the advantage of coming with Caffe installed (surprisingly), which I may end up using at some point.
The second issue I encountered was that using the GPU to run Lasagne’s enhanced example code on my full dataset was impossible due to memory constraints. The problem was that the example assumes that the entire dataset can fit in the GPU’s memory (as discussed here and here). This took a while to resolve, even though the solution is conceptually simple – just copy the dataset to the GPU in chunks rather than attempt to copy it all in one go. Resolving this issue was a good way of getting a better understanding of what the code does, since I ended up rewriting most of the original example code.
Next steps
So far, I left the network architecture from the original example mostly untouched, as I was busy collecting the dataset, getting the environment set up, and resolving various issues. One thing I did notice was that the example’s architecture diverges on my dataset, so instead I tested my code using a basic multi-layer perceptron architecture with a single hidden layer. This performs about as well as a random classifier on my dataset, but at least it converges. I also tested the modified code on the MNIST dataset and the results are decent, so now it is time to move forward and actually do some modelling, starting with convolutional neural nets.
The high level plan is to iteratively read tutorials/papers/books, implement ideas, play with parameters, and visualise parts of the network until I’m satisfied with the results. The main goal remains to learn as much as possible and get a good intuition of how things work. I’ll write more about my experiences in subsequent posts. Stay tuned!
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.