
Bandcamp Recommender (BCRecommender) is a web application that serves music recommendations from Bandcamp. I recently switched BCRecommender’s data store from MongoDB to Elasticsearch. This has made it possible to offer a richer search experience to users at a similar cost. This post describes the migration process and discusses some of the advantages and disadvantages of using Elasticsearch instead of MongoDB.
Motivation: Why swap MongoDB for Elasticsearch?
I’ve written a few posts in the past on BCRecommender’s design and implementation. It is a fairly simple application with two main components: the backend worker that crawls data and generates recommendations in batch, and the webapp that serves the recommendations. Importantly, each of these components has its own data store, with the recommendations synced up from the worker to the webapp, and data like events and subscriptions synced down from the webapp to the worker. Recently, I migrated the webapp component from Parse to DigitalOcean, replacing Parse’s data store with MongoDB. Choosing MongoDB was meant to simplify the transition – Parse uses MongoDB behind the scenes, as does the backend worker. However, moving out of Parse’s sandboxed environment freed me to choose any data store, and Elasticsearch seemed like a good candidate that would make it possible to expose advanced search capabilities to end users.
Advanced search means different things to different people. In BCRecommender’s case what I had in mind was rather modest, at least for the initial stages. BCRecommender presents recommendations for two types of entities: fans and tralbums (tracks/albums). In both cases, the recommended items are tralbums. When the key is a fan, the recommendations are tralbums that they may like, and when the key is a tralbum, the recommendations are similar tralbums. Each tralbum has a title, an artist name, and a list of tags. Each fan has its Bandcamp username as a primary key, and a list of tags that is derived from the tralbums in the fan’s collection. Originally, “searching” required users to either enter the exact username of a Bandcamp fan, or the exact Bandcamp link of a tralbum – not the best user experience! Indeed, I was tracking the search terms and found that many people were unsuccessfully trying to use unstructured queries. My idea of advanced search was to move away from the original key-value approach to full-text search that considers tags, titles, artists, and other fields that may get added later.
It was clear that while it may be possible to provide advanced search with MongoDB, it wouldn’t be a smooth ride. While recent versions of MongoDB include support for full-text search, it isn’t as feature-rich as Elasticsearch. For example, MongoDB text indices do not store phrases or information about the proximity of words in the documents, making phrase queries run slowly unless the entire collection fits in memory. The names really say it all: MongoDB is a database with some search capabilities, and Elasticsearch is a search engine with some database capabilities. It seems pretty common to use MongoDB (or another database) as a data store and supply search through Elasticsearch, so I figured it isn’t a bad idea to apply this pattern to BCRecommender.
It is worth noting that if BCRecommender were a for-profit project, I would probably use Algolia rather than Elasticsearch. My experience with Algolia on a different project has been excellent – they make it easy for you to get started, have great customer service, and deliver good and fast results with minimal development and operational effort. The two main disadvantages of Algolia are its price and the fact that it’s a closed-source solution (see further discussion on Quora). At over two million records, the monthly cost of running Algolia for BCRecommender would be around US$649, which is more than what I’m willing to spend on this project. However, for a business this may be a reasonable cost because deploying and maintaining an Elasticsearch cluster may end up costing more. Nonetheless, many businesses use Elasticsearch successfully, which is why I have no doubt that it’s a great choice for my use case – it just requires more work than Algolia to get up and running.
Executing the migration plan
The plan for migrating the webapp from MongoDB to Elasticsearch was pretty simple:
- Read the Elasticsearch manual to ensure it suits my needs
- Replace MongoDB with Elasticsearch without making any user-facing changes
- Expose full-text search to BCRecommender users
- Improve search performance based on user behaviour
- Implement more search features
Reading the manual is not something I do for every piece of technology I use (there are just too many tools out there these days), but for Elasticsearch it seemed to be worth the effort. I’m not done reading yet, but covering the material in the Getting Started and Search in Depth sections gave me enough information to complete steps 2 & 3. The main things I was worried about was Elasticsearch’s performance as a database and how memory-hungry it’d be. Reading the manual allowed me to avoid some memory-use pitfalls and gave me insights on the way MongoDB and Elasticsearch compare (see details below).
Switching from MongoDB to Elasticsearch as a simple database was pretty straightforward. Both are document-based, so there were no changes required to the data models, but I did use the opportunity to fix some issues. For example, I changed the sitemap generation process from dynamic to static to avoid having to scroll through the entire dataset to fetch deep sitemap pages. To support BCRecommender’s feature of browsing through random fans, I replaced MongoDB’s somewhat-hacky approach of returning random results with Elasticsearch’s cleaner method. As the webapp is implemented in Python, I originally used the elasticsearch-dsl package, but found it too hard to debug queries (e.g., figuring out how to rank results randomly was a bit of a nightmare). Instead, I ended up using the elasticsearch-py package, which is only a thin wrapper around the Elasticsearch API. This approach yields code that doesn’t look very Pythonic – rather than following the Zen of Python’s flat is better than nested aphorism, the API follows the more Java-esque belief of you can never have enough nesting (see image below for example). However, I prefer overly-nested structures that I can debug to flat code that doesn’t work. I may try using the DSL again in the future, once I’ve gained more experience with Elasticsearch.

As mentioned, one of my worries was that I would have to increase the amount of memory allocated to the machine where Elasticsearch runs. Since BCRecommender is a fairly low-budget project, I’m willing to sacrifice high availability to save a bit on operational costs. Therefore, the webapp and its data store run on the same DigitalOcean instance, which is enough to happily serve the current amount of traffic (around one request per second). By default, Elasticsearch indexes all the fields, and even includes an extra indexed _all field that is a concatenation of all string fields in a document. While indexing everything may be convenient, it wasn’t necessary for the first stage. Choosing the minimal index settings allowed me to keep using the same instance size as before (1GB RAM and 30GB SSD). In fact, due to the switch to static sitemaps and the removal of MongoDB’s random attribute hack, fewer indexes were required after the change.
Once I had all the code converted and working on my local Vagrant environment, it was time to deploy. The deployment was fairly straightforward and required no downtime, as I simply provisioned a new instance and switched over the floating IP once it was all tested and ready to go. I monitored response time and memory use closely and everything seemed to be working just fine – similarly to MongoDB. After a week of monitoring, it was time to take the next step and enable advanced search.
Enabling full-text search is where things got interesting. This phase required adding a search result page (previously users were redirected to the queried page if it was found), and reindexing the data. For this phase, I tried to keep things as simple as possible, and just indexed the string fields (tags, artist, and title) using the standard analyser. I did some manual testing of search results based on common queries, and played a bit with improving precision and recall. Perhaps the most important tweak was allowing an item’s activity level to influence the ranking. For each tralbum, the activity level is the number of fans that have the tralbum in their collection, and for each fan, it is the size of the collection. For example, when searching for amanda, the top result is the fan with username amanda, followed by tralbums by the popular Amanda Palmer. Before I added the consideration of activity level, all tralbums and fans that contained the word amanda had the same ranking.
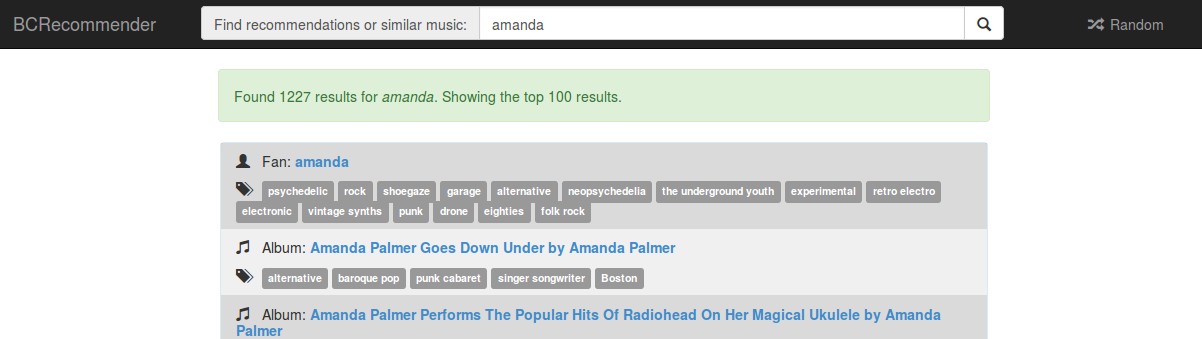
I deployed full-text search earlier this week, and so far it’s looking pretty good. Elasticsearch seems to be coping well with having the same level of resources allocated as before, but it’s still too early to tell if this is sustainable over time. Most importantly, users are finally seeing results when they enter unstructured queries, which increases their engagement and retention. Woohoo!
Improving search performance based on user behaviour is expected to be an ongoing effort. Despite having many ideas, I resisted the temptation of endless offline tinkering and opted to release a working search page quickly. With Google Analytics now set up to track site search, the plan is keep identifying gaps and tweak the search settings continuously. This will take a while, as the number of daily users is currently 200-300, and they don’t all use site search.
Implementing more search features is another set of items on my to-do list that will be addressed over time. For example, it’d be great to have search auto-completion and a prettier result page. However, I have more ideas than time to implement them, and I’m not working on BCRecommender full-time. For now, I’m pretty happy with finally having the search function.
Elasticsearch versus MongoDB: Key findings
Comparisons between tools should always be taken with a grain of salt. General comparisons may not address features that are important for your specific use case, or may overemphasise aspects that you don’t care about. In addition, actively developed tools are moving targets. Since I started the transition to Elasticsearch, version 2.0 has been released, and MongoDB 3.2 is expected very soon. The following list is derived from my experience and may not apply to you. You have been warned!
With the disclaimer out of the way, here are some of the advantages of Elasticsearch over MongoDB:
- Better full-text search support (duh!).
- Enforceable schemas and type validation (note: some form of optional schema is expected in MongoDB 3.2).
- All fields are indexed by default, making it easy to explore unstructured data without worrying about adding indices.
- It appears that indexing is implemented in a more efficient way that doesn’t block the node. Slowness due to indexing operations seems to be a common issue with MongoDB, even with background index creation.
- It’s possible to query multiple indices and types (same as MongoDB databases & collections, respectively) in the same query. This is a huge advantage in my case as it makes it possible to efficiently search both fans and tralbums in a single query.
- Index aliases make it easy to change the indices without changing the application.
- Multi-get by IDs returns results in the order they were requested. This is not the case with MongoDB, where using $in doesn’t have any guarantees on the returned documents’ order. It’s easy to work around this issue, but it can be the source of subtle bugs. In my case, recommendations were unintentionally sorted in random order until I added an additional step to sort them correctly.
- Built-in support for random scoring (note: random sampling will finally be available in MondoDB 3.2 – the ticket for this has been open for 5 years).
- Built-in support for multiple types of analysis on the same field.
Some disadvantages of Elasticsearch in comparison to MongoDB are:
- All fields are indexed by default, making it easy to run into memory issues. Adjusting these default settings is strongly recommended if you know how you’re going to query the data.
- Documents are immutable, so every update requires deleting the original document and re-inserting it (in practice, it seems like this isn’t much of an issue).
- Sorting results by a field requires reading all the field’s values and sorting them in memory. The sorted results are cached, but this may cause issues if memory is too limited.
In conclusion, my experience with Elasticsearch has been mostly positive so far and I’m glad I’ve made the switch. I’m looking forward to taking further advantage of advanced search features to improve user experience on BCRecommender. New posts on the topic may be published in the future, so please subscribe to be notified when this happens. As always, I’m happy to receive feedback through the comments or privately.
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.