
Many modern data scientists don’t get to experience data collection in the offline world. Recently, I spent a month sailing down the northern Great Barrier Reef, collecting data for the Reef Life Survey project. In addition to being a great diving experience, the trip helped me obtain general insights on data collection and machine learning, which are shared in this article.
The Reef Life Survey project
Reef Life Survey (RLS) is a citizen scientist project, led by a team from the University of Tasmania. The data collected by RLS volunteers is freely available on the RLS website, and has been used for producing various reports and scientific publications. An RLS survey is performed along a 50 metre tape, which is laid at a constant depth following a reef’s contour. After laying the tape, one diver takes photos of the bottom at 2.5 metre intervals along the transect line. These photos are automatically analysed to classify the type of substrate or growth (e.g., hard coral or sand). Divers then complete two swims along each side of the transect. On the first swim (method 1), divers record all the fish species and large swimming animals found in a 5 metre corridor from the line. The second swim (method 2) requires keeping closer to the bottom and looking under ledges and vegetation in a 1 metre corridor from the line, targeting invertebrates and cryptic animals. The RLS manual includes all the details on how surveys are performed.
Performing RLS surveys is not a trivial task. In the tropics, it is not uncommon to record around 100 fish species on method 1. The scientists running the project are very conscious of the importance of obtaining high-quality data, so training to become an RLS volunteer takes considerable effort and dedication. The process generally consists of doing surveys together with an experienced RLS diver, and comparing the data after each dive. Once the trainee’s data matches that of the experienced RLSer, they are considered good enough to perform surveys independently. However, retraining is often required when surveying new ecoregions (e.g., an RLSer trained in Sydney needs further training to survey the Great Barrier Reef).
RLS requires a lot of hard work, but there are many reasons why it’s worth the effort. As someone who cares about marine conservation, I like the fact that RLS dives yield useful data that is used to drive environmental management decisions. As a scuba diver, I enjoy the opportunity to dive places that are rarely dived and the enhanced knowledge of the marine environment – doing surveys makes me notice things that I would otherwise overlook. Finally, as a data scientist, I find the exposure to the work of marine scientists very educational.
Pre-training and thoughts on supervised learning
Doing surveys in the tropics is a completely different story from surveying temperate reefs, due to the substantially higher diversity and abundance of marine creatures. Producing high-quality results requires being able to identify most creatures underwater, while doing the survey. It is possible to write down descriptions and take photos of unidentified species, but doing this for a large number of species is impractical.
Training the neural network in my head to classify tropical fish by species was an interesting experience. The approach that worked best was making flashcards using reveal.js, photos scraped from various sources, and past survey data. As the image below shows, each flashcard consists of a single photo, and pressing the down arrow reveals the name of the creature. With some basic JavaScript, I made the presentation select a different subset of photos on each load. Originally, I tried to learn all the 1000+ species that were previously recorded in the northern Great Barrier Reef, but this proved to be too hard – I realised that a better strategy was needed. The strategy that I chose was to focus on the most frequently-recorded species: I started by memorising the most frequent ones (e.g., those recorded on more than 50% of surveys), and gradually made it more challenging by decreasing the frequency threshold (e.g., to 25% in 5% steps). This proved to be pretty effective – by the time I started diving I could identify about 50-100 species underwater, even though I had mostly been using static images. It’d be interesting to know whether this kind of approach would be effective in training neural networks (or other batch-trained models) in certain scenarios – spend a few epochs training with instances from a subset of the classes, and gradually increase the number of considered classes. This may be effective when errors on certain classes are more important than others, and may yield different results from simply weighting classes or instances. Please let me know if you know of anyone who has experimented with this idea (update: gwern from Reddit pointed me to the paper Curriculum Learning by Bengio et al., which discusses this idea).

RLS flashcard example (Chaetodon lunulatus)
While repeatedly looking at photos and their labels felt a lot like training an artificial neural network, as a human I have the advantage of being able to easily use information from multiple sources. For example, fish ID books such as Reef Fish Identification: Tropical Pacific provide concise descriptions of the identifying physical features of each fish (see the image below for the book’s entry for Chaetodon lunulatus – the butterflyfish from the flashcard above). Reading those descriptions made me learn more effectively, by helping me focus my attention on the parts that matter for classification. Learning only from static images can be hard when classifying creatures with highly variable colour schemes – using extraneous knowledge about what actually matters when it comes to classification is the way to go in practice. Further, features that are hard to decode from photos – like behaviour and habitat – are sometimes crucial to distinguishing different species. One interesting thought is that while photos can be seen as raw data, natural language descriptions are essentially models. Utilising such models is likely to be of benefit in many areas. For example, being able to tell a classifier what to look for in an image would make training a supervised classifier more similar to the way humans learn. This may be achieved using similar techniques to those used for generating image descriptions, except that the goal would be to use descriptions of the classes to improve classification accuracy.

Fish ID example (Chaetodon lunulatus). Source: Reef Fish Identification: Tropical Pacific
Another difference between my learning and supervised machine learning is that if I found a creature hard to identify, I would go and look for more photos or videos of them. Videos were especially valuable, because in practice I rarely had to identify static creatures. This approach may be applicable in situations where labelled data is abundant. Sometimes, using all the labelled data makes model training too slow to be practical. An approach I used in the past to overcome this issue is to randomly sample the data, but it often makes sense to sample in a way that yields the best model, e.g., by sampling more instances from classes that are harder to classify.
One similarity to supervised machine learning that I encountered was the danger of overfitting. Due to the relatively small number of photos and the fact that I had to view each one of them multiple times, I found that in some cases I memorised the entire photo rather than the creature. This was especially the case with low-quality photos or ones that were missing key features. My regularisation approach consisted of trying to memorise the descriptions from the book, and collecting more photos. I wish more algorithms were this self-conscious about overfitting!
Can’t this be automated?
While doing surveys and studying species, I kept asking myself whether the whole thing can be automated. Thanks to deep learning, computers have recently gotten very good at classifying images, sometimes outperforming humans. It seems likely that at some point the survey methodology would be changed to just taking a video of the dive, and letting an algorithm do the hard job of identifying the creatures. Analysis of the bottom photos is automated, so it is reasonable to automate the other survey methods as well. However, there are quite a few challenges that need to be overcome before full automation can be implemented.
If the results of the LifeCLEF 2015 Fish Task are any indication, we are quite far from automating fish identification. The precision of the top methods in that challenge was around 80% for identifying 15 fish species from underwater videos, where the chosen species are quite distinct from each other. In tropical surveys it is not uncommon to record around 100 fish species along the 50 metre transect, with many species being similar to each other. It’s usually the case that it’s not same species on every dive (even at the same site), so replacing humans would require training a highly accurate classifier on thousands of species.
Dealing with high diversity isn’t the only challenge in automating RLS. The appearance of many species varies by gender and age, so the classifier would have to learn all those variations (see image below for an example). Getting good training data can be very challenging, since the labelling process is labour-intensive, and elements like colour and backscatter are highly dependent on dive site conditions and the quality of the camera. Another complication is that RLS data includes size estimates, which can be hard to obtain from videos and photos without knowing how far the camera was from the subject and the type of lens used. In addition, accounting for side information (geolocation, behaviour, depth, etc.) can make a huge difference in accurately identifying species, but it isn’t easy to integrate with some learning models. Finally, it is likely that some species will be missed when videos are taken without any identification done underwater, because RLSers tend to get good photos of species that they know will be hard to identify, even if it means spending more time at one spot or shining strobes under ledges.

Chlorurus sordidus variations. Source: Tropical Marine Fishes of Australia
Another aspect of automating surveys is completely removing the need for human divers by sending robots down. This is an active research area, and is the only way of surveying deep waters. However, this approach still requires a boat-based crew to deploy the robots. It may also yield different data from RLS for cryptic species, though this depends on the type of robots used. In addition, there’s the issue of cost – RLS relies on volunteer scuba divers who are diving anyway, so the cost of getting RLSers to do surveys is rather low (especially for shore dives near a diver’s home, where there is no cost to RLS). Further, RLS’s mission is “to inspire and engage a global volunteer community to survey reefs using scientific methods and share knowledge about marine ecosystem health”. Engaging the community is a crucial part of RLS because robots do not care about the environment. Humans do.
Small data is valuable
When compared to datasets commonly encountered online, RLS data is small. As the image below shows, fewer than 10,000 surveys have been conducted to date. However, this data is still valuable, as it provides a high-quality snapshot of the state of marine ecosystems in areas that wouldn’t be surveyed if it wasn’t for RLS volunteers. For example, in a recent Nature article, the authors used RLS data to assess the vulnerability of marine fauna to global warming.
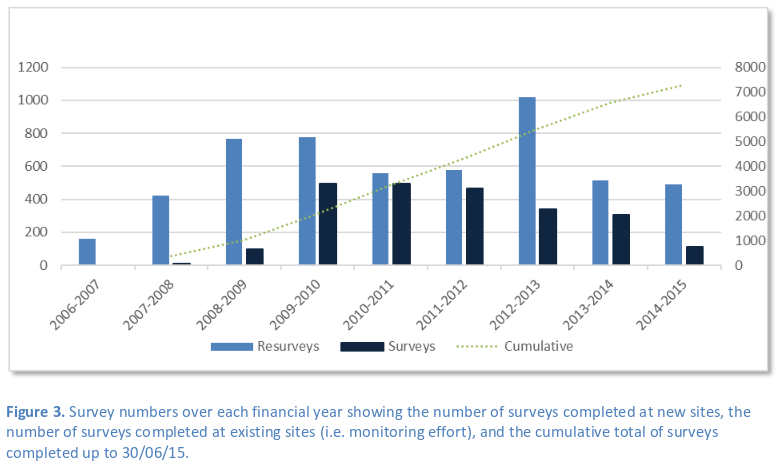
RLS surveys by Australian financial year (July-June). Source: RLS Foundation Annual Report 2015
Each RLS survey requires several hours of work. In addition to performing the survey itself, a lot of work goes into entering the data and verifying its quality. Getting to the survey sites is not always a trivial task, especially for remote sites such as some of those we dived on my recent trip. Spending a month diving the Great Barrier Reef is a good way of appreciating its greatness. As the map shows, the surveys we did covered only the top part of the reef’s 2300 kilometres, and we only sampled a few sites within that part. The Great Barrier Reef is very vast, and it is hard to convey its vastness with just words or a map. You have to be there to understand – it is quite humbling.
In summary, the RLS experience has given me a new appreciation for small data in the offline world. Offline data collection is often expensive and labour-intensive – you need to work hard to produce a few high-quality data points. But the size of your data doesn’t matter (though having more quality data is always good). What really matters is what you do with the data – and the RLS team and their collaborators have been doing quite a lot. The RLS experience also illustrates the importance of domain expertise: I’ve looked at the RLS datasets, but I have no idea what questions are worth asking and answering using those datasets. The RLS project is yet another example of how in science collecting data is time-consuming, and coming up with appropriate research questions is hard. It is a lot of fun, though.
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.