The study of causality and causal inference is central to science in general and data science in particular. Being able to distinguish between correlation and causation is key to designing effective interventions in business, public policy, medicine, and many other fields. There are quite a few approaches to inferring causal relationships from data. In this post, I discuss some aspects of Judea Pearl’s graphical modelling approach, and how its limitations are addressed in recent work by Samantha Kleinberg. I then finish with a brief survey of the Bradford Hill criteria and their applicability to a key limitation of all causal inference methods: The need for untested assumptions.
Judea Pearl
Overcoming my Pearl bias
First, I must disclose that I have a personal bias in favour of Pearl’s work. While I’ve never met him, Pearl is my academic grandfather – he was the PhD advisor of my main PhD supervisor (Ingrid Zukerman). My first serious exposure to his work was through a Sydney reading group, where we discussed parts of Pearl’s approach to causal inference. Recently, I refreshed my knowledge of Pearl causality by reading Causal inference in statistics: An overview. I am by no means an expert in Pearl’s huge body of work, but I think I understand enough of it to write something of use.
Pearl’s theory of causality employs Bayesian networks to represent causal structures. These are directed acyclic graphs, where each vertex represents a variable, and an edge from X to Y implies that X causes Y. Pearl also introduces the do(X) operator, which simulates interventions by removing all the causes of X, setting it to a constant. There is much more to this theory, but two of its main contributions are the formalisation of causal concepts that are often given only a verbal treatment, and the explicit encoding of causal assumptions. These assumptions must be made by the modeller based on background knowledge, and are encoded in the graph’s structure – a missing edge between two vertices indicates that there is no direct causal relationship between the two variables.
My main issue with Pearl’s treatment of causality is that he doesn’t explicitly handle time. While time can be encoded into Pearl’s models (e.g., via dynamic Bayesian networks), there is nothing that prevents creation of models where the future causes changes in the past. A closely-related issue is that Pearl’s causal models must be directed acyclic graphs, making it hard to model feedback loops. For example, Pearl says that “mud does not cause rain”, but this isn’t true – water from mud evaporates, causing rain (which causes mud). What’s true is that “mud now doesn’t cause rain now” or something along these lines, which is something that must be accounted for by adding temporal information to the models.
Nonetheless, Pearl’s theory is an important step forward in the study of causality. In his words, “in the bulk of the statistical literature before 2000, causal claims rarely appear in the mathematics. They surface only in the verbal interpretation that investigators occasionally attach to certain associations, and in the verbal description with which investigators justify assumptions.” The importance of formal causal analysis cannot be overstated, as it underlies many decisions that affect our lives. However, it seems to me like there’s still plenty of work to be done before causal analysis becomes as established as other statistical tools.
Samantha Kleinberg
Kleinberg: Addressing gaps in Pearl’s work
I recently finished reading Samantha Kleinberg’s Causality, Probability, and Time. Kleinberg dedicates a good portion of the book to presenting the history of causality and discussing its many definitions. As hinted by the book’s title, Kleinberg believes that one cannot discuss causality without considering time. In her words: “One of the most critical pieces of information about causality, though – the time it takes for the cause to produce its effect – has been largely ignored by both philosophical theories and computational methods. If we do not know when the effect will occur, we have little hope of being able to act successfully using the causal relationship.” Following this assertion, Kleinberg presents a new approach to causal inference that is based on probabilistic computation tree logic (PCTL). With PCTL, one can concisely express probabilistic temporal statements. For example, if we observe a potential cause c occurring at time t, and a possible effect e occurring at time t’, we can use PCTL to state the hypothesis that in general, after c becomes true, it takes between one and |t’ – t| time units for e to become true with probability at least p, i.e., c leads to e:
It is obvious why PCTL may be a better fit than Bayesian networks for expressing causal statements. For example, with a Bayesian network, we can easily express the statement that smoking causes lung cancer with probability 0.3, but this isn’t that useful, as it doesn’t tell us how long it’ll take for cancer to develop. With PCTL, we can state that smoking causes lung cancer in 5-30 years with probability at least 0.3. This matches our knowledge that cancer doesn’t develop immediately – one cigarette won’t kill you.
One of the key concepts introduced by Kleinberg is that of causal significance. Calculating the causal significance of a cause c to an effect e relies on first identifying the set X of potential (or prima facie) causes of e. The set X contains all discrete variables x such that E[e|x]≠E[e] and x occurs earlier than e. Given the set X, the causal significance of c to e is the mean of E[e|c∧x] – E[e|¬c∧x] for all x≠c. The intuition is that if a cause c is significant, its causal significance value will be high when other potential causes are held fixed. For example, if c is heavy smoking and e is severity of lung cancer (with e=0 meaning no cancer), the expected value of e given c is likely to be higher than the expected value of e given ¬c, when conditioned on any other potential cause. Once causal significance has been measured, we can separate significant causes from insignificant causes by setting a threshold on causal significance values (this threshold can be inferred from the data). Significant causes are considered to be genuine if the data is stationary and the common causes of all pairs of variables have been included, which is a very strong condition that may be hard to fulfil in realistic scenarios. However, causal significance is an evolving concept – last year, Huang and Kleinberg introduced a new definition of causal significance that can be inferred faster and yield more accurate results. My general feeling is that this line of research will continue to yield many interesting and useful results in coming years.
Kleinberg’s work is not without its limitations. In addition to the assumptions that causal relationships are stationary and the requirement to identify all potential causes, the recently-introduced definition of causal significance also requires the relationships to be linear and additive (though this limitation may be relaxed in future work). Another issue is that most of the evaluation in the studies I’ve read was done on synthetic datasets. While there are some results on real-life health and finance data, I find it hard to judge the practicality of utilising Kleinberg’s methods without applying them to problems that I’m more familiar with. Finally, as with other work in the field of causal inference, we need to have some degree of belief in untested assumptions to reach useful conclusions. In Kleinberg’s words:
Thus, a just so cause is genuine in the case where all of the outlined assumptions hold (namely that all common causes are included, the structure is representative of the system and, when data is used, a formula satisfied by the data will be satisfied by the structure). Our belief in whether a cause is genuine, in the case where it is not certain that the assumptions hold, should be proportional to how much we believe that the assumptions are true.
Austin Bradford Hill
Hill: Testing untested assumptions
To the best of my knowledge, all causal inference methods rely on untested assumptions. Specifically, we can never include all the variables in the universe in our models. Therefore, any conclusions drawn are reliant on deciding what, when, and how to measure potential causes and effects. Another issue is that no matter how good and believable our modelling is, we cannot use causal inference to convince unreasonable people. For example, some people may cite divine intervention as an unmeasurable cause of anything and everything. In addition, people with certain commercial interests often try to raise doubt about well-established causal mechanisms by making unreasonable claims for evidence of various hidden factors. For example, tobacco companies used to claim that both smoking and lung cancer were caused by a common hidden factor, making the link between smoking and lung cancer a mere association.
Assuming that we are dealing with reasonable people, there’s still the question of where we should get our untested assumptions from. This question is fairly old, and has been partly answered in 1965 by Austin Bradford Hill, with nine criteria that he recommended should be considered before calling an association causal:
Strength: How strong is the association? For example, lung cancer deaths of heavy smokers are 20-30 times greater than those of non-smokers.
Consistency: Has the association been repeatedly observed in various circumstances? For example, many different populations have exhibited an association between smoking rates and cancer.
Specificity: Can we pin down specific instances of the effect to specific instances of the cause? Hill sees this as a nice-to-have condition rather than a must-have – cases with multiple possible causes may not fulfil the specificity requirement.
Temporality: Do we know that c leads to e or are we observing them together? This is a condition that isn’t always easy to fulfil, especially when dealing with feedback loops and slow processes.
Biological gradient: Hill’s focus was on medicine, and this condition refers to the association exhibiting some dose-response curve. This can be generalised to other fields, as we can expect some regularity in the effect if it is a function of the cause (though it doesn’t have to be a linear function).
Plausibility: Do we know of a mechanism that can explain how the cause brings about the effect?
Coherence: Does the association conflict with our current knowledge? Even if it does, it isn’t enough to rule out causality, as our current knowledge may be incomplete or wrong.
Experiment: If possible, running controlled experiments may yield very powerful evidence in favour of causation.
Analogy: Do we know of any similar cause-and-effect relationships?
Hill summarises the list of criteria (or viewpoints) with the following statements.
Here then are nine different viewpoints from all of which we should study association before we cry causation. What I do not believe – and this has been suggested – is that we can usefully lay down some hard-and-fast rules of evidence that must be obeyed before we accept cause and effect. None of my nine viewpoints can bring indisputable evidence for or against the cause-and-effect hypothesis and none can be required as a sine qua non. What they can do, with greater or less strength, is to help us to make up our minds on the fundamental question – is there any other way of explaining the set of facts before us, is there any other answer equally, or more, likely than cause and effect?
No formal tests of significance can answer those questions. Such tests can, and should, remind us of the effects that the play of chance can create, and they will instruct us in the likely magnitude of those effects. Beyond that they contribute nothing to the ‘proof’ of our hypothesis.
This post has only scratched the surface of the vast field of study of causality. At this point, I feel like I’ve read quite a bit, and it is time to apply what I learned to real problems. I encounter questions of causality in my everyday work, but haven’t fully applied formal causal inference to any problem yet. My view is that everyone needs to at least be aware of the need to consider causality, and of what it’d take to truly prove causal impact. A large proportion of what many people need in practice may be addressed by Hill’s criteria, rather than by formal methods for causal analysis. Nonetheless, I will report back when I get a chance to apply formal causal inference to real datasets. Stay tuned!
Public comments are closed, but I love hearing from readers. Feel free to
contact me with your thoughts.
Interesting point on the causal significance. How does this work when you have confounders in x? I’d have thought that x must contain the set of prima facie causes for which we have true exogenous variation.
Also, how does it work when you have bad controls in x (where x includes post-treatment causes that are plausibly varied by c)?
To be honest, I’m not completely sure it works in all these cases, as there is always a need for interpretation to decide whether the identified causes are genuine. I tried playing a bit with the toy data from Pearl’s report on Simpson’s Paradox, but the results are not entirely convincing. However, I’m also not fully convinced that Pearl’s solution fully resolves Simpson’s Paradox, and Kleinberg does go through a few scenarios where her approach doesn’t work in her book, so I’d say that there are still quite a few open problems in the area.
Post-treatment causes are partly addressed by the definition in Huang and Kleinberg (2015), where significance is weighted by the number of timepoints where e follows c. Again, that definition doesn’t handle all cases, but I think it’s an interesting line of research. I would definitely like to see their results reproduced by other researchers and expanded to other datasets, though.
Great post. I did not know about Kleinberg and Hill’s work. I knew a similar list of criteria from this article, which is much younger https://doi.org/10.1177%2F0951629805050859
Regarding Kleinberg: Adding time certainly is valuable, but doesn’t the smoking example change the research question from whether smoking causes lung cancer to when it causes lung cancer? The latter question is more informative and implies the former, but I’d say it is fine to ask the first question when one is not interested in the time of occurrence of cancer.
Thank you! I agree that the latter question is more informative, but I now think that saying that “smoking causes cancer” isn’t particularly meaningful, as it ignores both timing and dosage. A good summary of the case for well-defined interventions was provided by Miguel Hernán in this paper: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5207342/
The limits of Pearl’s theory on feedback loops bothers me too. However, have you studied much Control Theory? Or dynamical systems in general? It explicitly deals with feedback loops. I’d be keen to get your thoughts on the comparison of Control Theory vs Pearl’s Causal Inference.





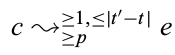


Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.
James Savage
2016-05-15 21:49:50
Interesting point on the causal significance. How does this work when you have confounders in x? I’d have thought that x must contain the set of prima facie causes for which we have true exogenous variation.
Also, how does it work when you have bad controls in x (where x includes post-treatment causes that are plausibly varied by c)?
Yanir Seroussi
2016-05-16 21:29:51
Good questions :)
To be honest, I’m not completely sure it works in all these cases, as there is always a need for interpretation to decide whether the identified causes are genuine. I tried playing a bit with the toy data from Pearl’s report on Simpson’s Paradox, but the results are not entirely convincing. However, I’m also not fully convinced that Pearl’s solution fully resolves Simpson’s Paradox, and Kleinberg does go through a few scenarios where her approach doesn’t work in her book, so I’d say that there are still quite a few open problems in the area.
Post-treatment causes are partly addressed by the definition in Huang and Kleinberg (2015), where significance is weighted by the number of timepoints where e follows c. Again, that definition doesn’t handle all cases, but I think it’s an interesting line of research. I would definitely like to see their results reproduced by other researchers and expanded to other datasets, though.
Jose Magana
2016-05-17 01:19:40
Rachel Lynne Wilkerson
2016-12-08 11:26:40
rs
2017-03-23 06:57:16
ingorohlfing
2018-12-30 19:33:12
Yanir Seroussi
2018-12-31 01:25:05
locksley1
2021-01-02 11:44:23
Yanir Seroussi
2021-01-03 01:07:36