
Data science can be defined as either the intersection or union of software engineering and statistics. In recent years, the field seems to be gravitating towards the broader unifying definition, where everyone who touches data in some way can call themselves a data scientist. Hence, while many people whose job title is Data Scientist do very useful work, the title itself has become fairly useless as an indication of what the title holder actually does. This post briefly discusses how we got to this point, where I think the field is likely to go, and what data scientists can do to remain relevant.
The many definitions of data science
About two years ago, I published a post discussing the definition of data scientist by Josh Wills, as a person who is better at statistics than any software engineer and better at software engineering than any statistician. I still quite like this definition, because it describes me well, as someone with education and experience in both areas. However, to be better at statistics than any software engineer and better at software engineering than any statistician, you have to be truly proficient in both areas, as some software engineers are comfortable running complex experiments, and some statisticians are capable of building solid software. Quite a few people who don’t meet Wills’s criteria have decided they wanted to be data scientists too, expanding the definition to be something along the lines of someone who is better at statistics than some software engineers (who’ve never done anything fancier than calculating a sample mean) and better at software engineering than some statisticians (who can’t code).
In addition to software engineering and statistics, data scientists are expected to deeply understand the domain in which they operate, and be excellent communicators. This leads to the proliferation of increasingly ridiculous Venn diagrams, such as the one by Stephan Kolassa:
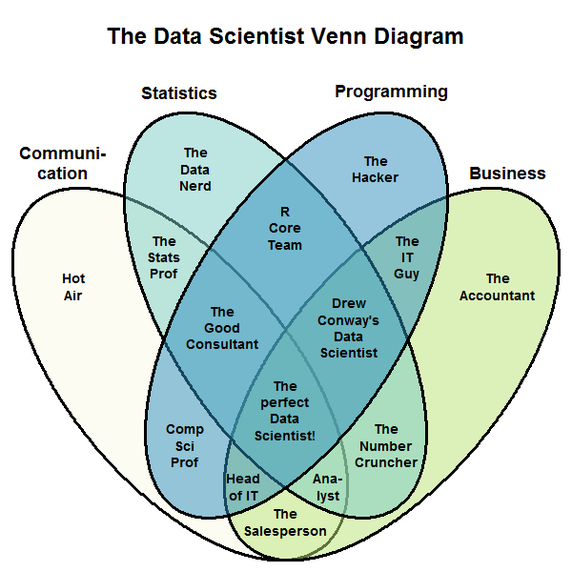
The perfect data scientist from Kolassa’s Venn diagram is a mythical sexy unicorn ninja rockstar who can transform a business just by thinking about its problems. A more realistic (and less exciting) view of data scientists is offered by Rob Hyndman:
I take the broad inclusive view. I am a data scientist because I do data analysis, and I do research on the methodology of data analysis. The way I would express it is that I’m a data scientist with a statistical perspective and training. Other data scientists will have different perspectives and different training.
We are comfortable with having medical specialists, and we will go to a GP, endocrinologist, physiotherapist, etc., when we have medical problems. We also need to take a team perspective on data science.
None of us can realistically cover the whole field, and so we specialise on certain problems and techniques. It is crazy to think that a doctor must know everything, and it is just as crazy to think a data scientist should be an expert in statistics, mathematics, computing, programming, the application discipline, etc. Instead, we need teams of data scientists with different skills, with each being aware of the boundary of their expertise, and who to call in for help when required.
Indeed, data science is too broad for any data scientist to fully master all areas of expertise. Despite the misleading name of the field, it encompasses both science and engineering, which is why data scientists can be categorised into two types, as suggested by Michael Hochster:
- Type A (analyst): focused on static data analysis. Essentially a statistician with coding skills.
- Type B (builder): focused on building data products. Essentially a software engineer with knowledge in machine learning and statistics.
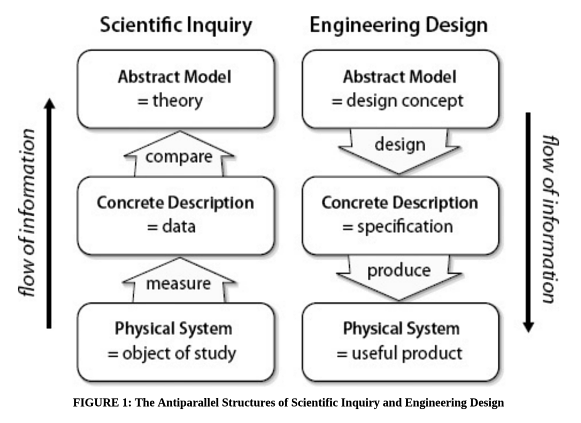
Type A is more of a scientist, and Type B is more of an engineer. Many people end up doing both, but it is pretty rare to have an even 50-50 split between the science and engineering sides, as they require different mindsets. This is illustrated by the following diagram, showing the information flow in science and engineering (source).
Why Data Scientist is a useless job title
Given that a data scientist is someone who does data analysis, and/or a scientist, and/or an engineer, what does it mean for a person to hold a Data Scientist position? It can mean anything, as it depends on the company and industry. A job title like Data Scientist at Company is about as meaningful as Engineer at Organisation, Scientist at Institution, or Doctor at Hospital. It gives you a general idea what the person’s background is, but provides little clue as to what the person actually does on a day-to-day basis.
Don’t believe me? Let’s look at a few examples. Noah Lorang (Basecamp) is OK with mostly doing arithmetic. David Robinson (Stack Overflow) builds machine learning features and internal R packages, and visualises data. Robert Chang (Twitter) helps surface product insights, create data pipelines, run A/B tests, and build predictive models. Rob Hyndman (Monash University) and Jake VanderPlas (University of Washington) are academic data scientists who contribute to major R and Python open-source libraries, respectively. From personal knowledge, data scientists in many Australian enterprises focus on generating reports and building dashboards. And in my current role at Car Next Door I do a little bit of everything, e.g., implement new features, fix bugs, set up data pipelines and dashboards, run experiments, build predictive models, and analyse data.
To be clear, the work done by many data scientists is very useful. The number of decisions made based on arbitrary thresholds and some means multiplied together on a spreadsheet can be horrifying to those of us with minimal knowledge of basic statistics. Having a good data scientist on board can have a transformative effect on a business. But it’s also very easy to end up with ineffective hires working on low-impact tasks if the business has no idea what their data scientists should be doing. This situation isn’t uncommon, given the wide range of activities that may be performed by data scientists, the lack of consensus on the definition of the field, and a general disagreement over who deserves to be called a real data scientist. We need to move beyond the hype towards clearer definitions that would help align the expectations of data scientists with those of their current and future employers.
It’s time to specialise
Four years ago, I changed my LinkedIn title from software engineer with a research background to data scientist. Various offers started coming my way, and they haven’t stopped since. Many people have done the same. To be a data scientist, you just need to call yourself a data scientist. The dilution of the term means that as a job title, it is useless. Useless terms are unlikely to last, so if you’re seriously thinking of becoming a data scientist, you should also consider specialising. I believe we’ll see the emergence of new specific titles, such as Machine Learning Engineer. In addition, less “sexy” titles, such as Data Analyst, may end up making a comeback. In any case, those of us who invest in building their skills, delivering value in their job, and making sure people know about it don’t have much to worry about.
What do you think? Is specialisation inevitable or are generalist data scientists here to stay? Please let me know privately, via Twitter, or in the comments section.
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.
justalanm
2016-08-05 07:45:57
I think exactly the same, but for the moment the title is somewhat needed. I’ll make my example: I’m a data scientist because my company wants to differentiate between regular data analysts (who can’t code but are learning with me helping them) and backend software engineers who can code better than me, but lack the business knowledge and have the tendency to trow fancy algorithms at numbers without thinking about method and usefulness for the business.
Eventually we will have new job titles, but for now we are stuck with “data scientists”. As soon as the hype will fade we’ll see people moving to new titles.
wesleypasfield
2016-08-09 21:33:26
Ian Miller
2016-08-15 15:36:44
Good article - I’ve always had a bit of problem with the term “Data Scientist” in that it infers that the person with such a title is somehow involved in research of data for scientific purposes or has a deep academic background neither of which are usually true.
Now, what does everyone think about the term “Data Architect” - I could do a rant on that one. Suffice it to say, you are a DATABASE Architect, not a DATA architect. Data is data, it is just raw numbers. You don’t design data, you design a data model which eventually gets translated into a database. Sorry, I guess that was a bit of a rant …
Yanir Seroussi
2016-08-15 19:34:35
Jonathan Sunderland
2016-08-31 06:49:40
Great article, and couldn’t agree more - there’s deep irony in “Data Science” as a job title.
I’ve started to use the term “Entrepreneurial Analyst” to be more precise about the focus on the outcome and also to allow latitude for hypotheses, exploration and discovery.
Elena
2016-09-08 15:13:14
Bernard Clyde
2017-02-21 21:21:37
aileenscott604
2017-07-17 11:47:15