
Bootstrap sampling techniques are very appealing, as they don’t require knowing much about statistics and opaque formulas. Instead, all one needs to do is resample the given data many times, and calculate the desired statistics. Therefore, bootstrapping has been promoted as an easy way of modelling uncertainty to hackers who don’t have much statistical knowledge. For example, the main thesis of the excellent Statistics for Hackers talk by Jake VanderPlas is: “If you can write a for-loop, you can do statistics”. Similar ground was covered by Erik Bernhardsson in The Hacker’s Guide to Uncertainty Estimates, which provides more use cases for bootstrapping (with code examples). However, I’ve learned in the past few weeks that there are quite a few pitfalls in bootstrapping. Much of what I’ve learned is summarised in a paper titled What Teachers Should Know about the Bootstrap: Resampling in the Undergraduate Statistics Curriculum by Tim Hesterberg. I doubt that many hackers would be motivated to read a paper with such a title, so my goal with this post is to make some of my discoveries more accessible to a wider audience. To learn more about the issues raised in this post, it’s worth reading Hesterberg’s paper and other linked resources.
For quick reference, here’s a summary of the advice in this post:
- Use an accurate method for estimating confidence intervals
- Use enough resamples – at least 10-15K
- Don’t compare confidence intervals visually
- Ensure that the basic assumptions apply to your situation
Pitfall #1: Inaccurate confidence intervals
Confidence intervals are a common way of quantifying the uncertainty in an estimate of a population parameter. The percentile method is one of the simplest bootstrapping approaches for generating confidence intervals. For example, let’s say we have a data sample of size n and we want to estimate a 95% confidence interval for the population mean. We take r bootstrap resamples from the original data sample, where each resample is a sample with replacement of size n. We calculate the mean of each resample and store the means in a sorted array. We then return the 95% confidence interval as the values that fall at the 0.025r and 0.975r indices of the sorted array (i.e., the 2.5% and 97.5% percentiles). The following table shows what the first two resamples may look like for a data sample of size n=5.
| Original sample | Resample #1 | Resample #2 | … | |
|---|---|---|---|---|
| Values | 10 | 30 | 20 | … |
| 12 | 20 | 20 | ||
| 20 | 12 | 30 | ||
| 30 | 12 | 30 | ||
| 45 | 45 | 30 | ||
| Mean | 23.4 | 23.8 | 26 | … |
The percentile method is nice and simple. Any programmer should be able to easily implement it in their favourite programming language, assuming they can actually program. Unfortunately, this method is just not accurate enough for small sample sizes. Quoting Hesterberg (emphasis mine):
The sample sizes needed for different intervals to satisfy the “reasonably accurate” (off by no more than 10% on each side) criterion are: n ≥ 101 for the bootstrap t, 220 for the skewness-adjusted t statistic, 2,235 for expanded percentile, 2,383 for percentile, 4,815 for ordinary t (which I have rounded up to 5,000 above), 5,063 for t with bootstrap standard errors and something over 8,000 for the reverse percentile method.
In a shorter version of the paper cited above, Hesterberg concludes that:
In practice, implementing some of the more accurate bootstrap methods is difficult (especially those not described here), and people should use a package rather than attempt this themselves.
In short, make sure you’re using an accurate method for estimating confidence intervals when dealing with sample sizes of less than a few thousand values. Using a package is a great idea, but unfortunately I don’t know of any Python bootstrapping package that is feature-complete: ARCH and scikits-bootstrap support advanced confidence interval methods but don’t support analysis of two samples of uneven sizes, while bootstrapped works with samples of uneven sizes but only supports the percentile and the reverse percentile method (which Hesterberg found to be even less accurate). If you know of any better Python packages, please let me know! (I don’t use R, but I suspect the situation is better there). Update: ARCH now supports analysis of samples of uneven sizes following an issue I reported. It seems to be the best Python bootstrapping package, so I recommend using it.
Pitfall #2: Not enough resamples
Accurate bootstrap estimates require a large number of resamples. Many code snippets use 1,000 resamples, probably because it looks like a large number. However, seeming large isn’t enough. Quoting Hesterberg again:
For both the bootstrap and permutation tests, the number of resamples needs to be 15,000 or more, for 95% probability that simulation-based one-sided levels fall within 10% of the true values, for 95% intervals and 5% tests. I recommend r = 10,000 for routine use, and more when accuracy matters.
[…]
We want decisions to depend on the data, not random variation in the Monte Carlo implementation. We used r = 500,000 in the Verizon project.
That’s right, half a million resamples! Accuracy mattered in the Verizon case, as the results of the analysis determined whether large penalties were paid or not. In short, use at least 10-15,000 resamples to be safe. Don’t use 1,000.
Pitfall #3: Comparison of single-sample confidence intervals
Confidence intervals are commonly used to decide if the difference between two samples is statistically significant. Bootstrapping provides a straightforward way of estimating confidence intervals without making assumptions about the way the data was generated. For example, given two samples, we can obtain confidence intervals for the mean of each sample and end up with a plot like this:
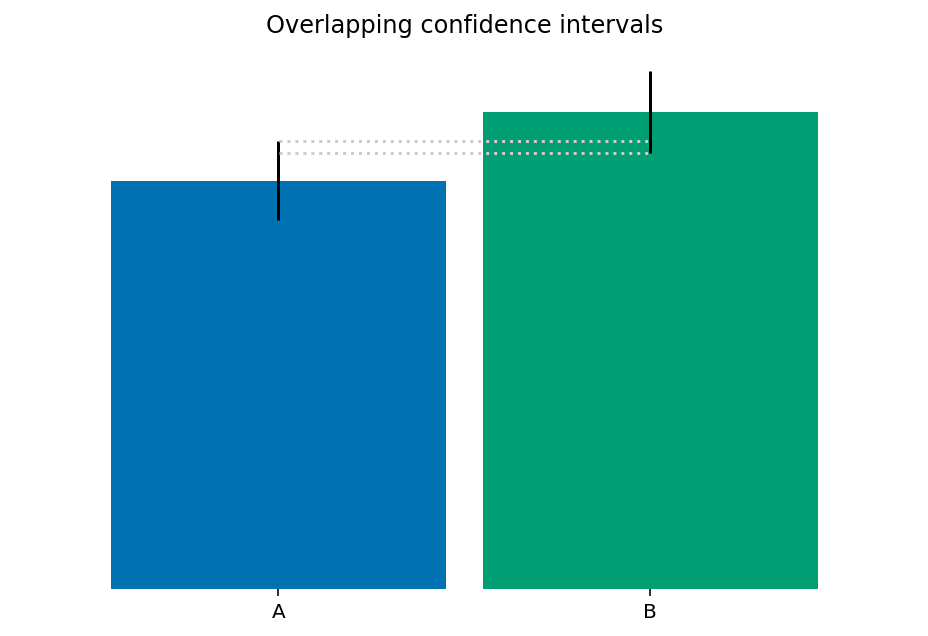
When looking at this plot, some people may conclude that the difference between the groups isn’t statistically significant because the confidence intervals overlap. However, overlapping confidence intervals don’t imply a lack of statistical significance because it is possible for the confidence interval of the difference between the sample means to not contain zero. Prasanna Parasurama explained why this happens in this post. While this issue isn’t unique to bootstrapping, it’s worth remembering that when comparing two groups, we need to obtain the confidence interval for the difference in the parameter we’re comparing, not compare single-sample confidence intervals.
For a concrete example, consider a case where we’re looking at a binary outcomes (yes/no or 1/0), which occur in coin flips or online A/B tests. Sample A consists of 2,150 zeroes and 350 ones, while sample B consists of 2,250 zeroes and 440 ones. As these are fairly large samples, we can use the bootstrap percentile method to obtain 95% confidence intervals for the mean of each sample. As the following figure shows, these intervals overlap. If we use the same method to also obtain a 95% confidence interval for the difference in means between B and A, we see that it doesn’t include zero. Therefore, we can say that the difference between B and A is statistically significant, despite the overlap between the single-sample confidence intervals.
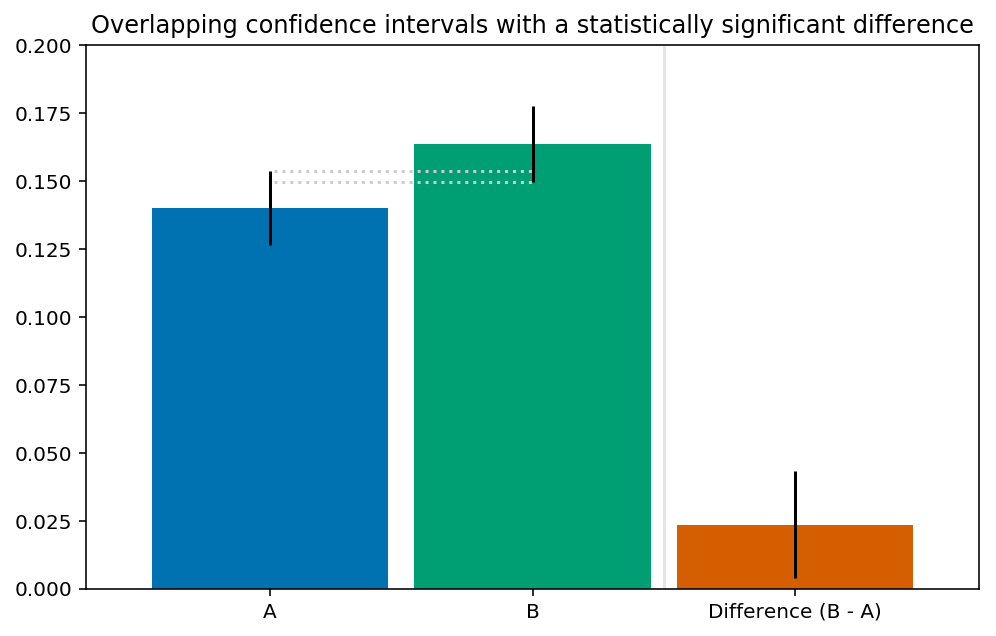
It’s worth noting that when analysing binary outcomes, we can make stronger assumptions about the data rather than use bootstrapping to obtain confidence intervals. Erik Bernhardsson suggests using the Beta distribution to obtain single-sample confidence intervals, but as we’ve seen, they don’t tell us enough about the differences between samples. I suggested using a Bayesian approach in the past, which makes explicit modelling assumptions that allow us to encode our prior knowledge on the specific environment where the data was generated. For example, when running online A/B tests, we often have a ballpark figure for reasonable results, which can be used in the Bayesian A/B testing calculator I built.
Pitfall #4: Unrepresentative and dependent samples
While the basic bootstrap makes no assumption about the underlying distribution of the data, it is not assumption-free. For example, when dealing with correlated data points from a time series, using the basic bootstrapping approach is wrong because it assumes that the data points are independent. Instead, a block bootstrap should be used – see the ARCH package for some implementation examples. In addition, bootstrapping doesn’t solve problems with the underlying sampling approach. For example, the data sample may not be representative of the population because of its small size, or there may be selection biases and measurement errors. No amount of bootstrapping is going to help with such issues. In general, it always helps to be aware of the data’s generation process, e.g., different considerations apply when dealing with data from online experiments versus observational studies.
Conclusion and next steps
While bootstrapping is a powerful method, its initial impression of simplicity is misleading. To draw valid conclusions, it’s a good idea to use a package and be aware of considerations that are specific to the analysed data sample. However, if you’re already increasing your awareness of the data and its generation process, it may make sense to explicitly encode your assumptions in the model. This is where another hacker resource would come in handy: Probabilistic Programming & Bayesian Methods for Hackers by Cam Davidson-Pilon. Admittedly, it’s a bit longer than the average blog post or conference talk, but it is worth reading.
Going down the bootstrapping rabbit hole has reminded me of an important lesson: Blog posts and talks – especially ones with the word hacker in the title – may be a good starting point, but they shouldn’t be relied on for serious work. Instead, it is better to consult peer-reviewed resources and textbooks, such as the references listed in ARCH’s documentation. In my future explorations of bootstrapping and other methods, I will heed Abraham Lincoln’s timeless advice to not trust everything I read on the internet.

Update (Oct 2019): I published a post summarising a talk I gave on the topic, complete with simulation code that illustrates the issues with some bootstrapping algorithms.
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.
Ralph Haygood
2019-01-08 00:09:43
Ingo Rohlfing
2019-01-09 09:52:57
Ingo Rohlfing
2019-01-09 12:21:19
Boris Gorelik
2019-01-15 12:38:17
Reblogged this on Boris Gorelik and commented:
Anything is better when bootstrapped. Read my co-worker’s post on bootstrapping. Also make sure following the links Yanir gives to support his claims