The passage of time makes wizards of us all. Today, any dullard can make bells ring across the ocean by tapping out phone numbers, cause inanimate toys to march by barking an order, or activate remote devices by touching a wireless screen. Thomas Edison couldn’t have managed any of this at his peak—and shortly before his time, such powers would have been considered the unique realm of God.
Being a data scientist can sometimes feel like a race against software innovations. Every interesting and useful problem is bound to become a software commodity. My story seems to reflect that: From my first steps in sentiment analysis and topic modelling, through building recommender systems while dabbling in Kaggle competitions and deep learning a few years ago, and to my present-day interest in causal inference. What can one do to remain relevant in such an environment? Read this post to find out.
Highlights from my past
When I started my PhD in 2009, the plan was to work on sentiment analysis of opinion polls. This got me into applied machine learning using Java and Weka, with which I made some modest contributions to the field. Today, researching sentiment analysis would feel somewhat pointless, given the plethora of sentiment analysis services. Sentiment analysis is a commodity – using it in practice is a software engineering problem.
Moving forward in my PhD, I got into topic modelling. I learned about Bayesian statistics and conjugate priors. I went through the arduous process of solving integrals by hand and coding a custom Gibbs sampler for the models I specified. Today, I probably wouldn’t bother with the maths. Instead, I’d specify the model and let a probabilistic programming tool like pymc3 or Stan handle the rest. Bayesian inference is now a commodity that’s accessible to any hacker.

A part of my PhD thesis that can probably be replaced by a probabilistic programming tool
Towards the end of my PhD in 2012, I got into Kaggle competitions. Back then, it seemed like “real” data science consisted of building and tuning machine learning models – that’s what Kaggle was all about. While I’ve done quite well in those competitions, I’ve come to realise that the utility of fine-tuning machine learning algorithms is quite limited. In reality, problem definition and solution measurement are more challenging and important. Using machine learning in practice is typically an engineering problem: We can use an existing service or package, follow best practices, and have a great solution for most use cases. No research or custom data work is required beyond turning data into features, which is essentially a data engineering problem. In short, solid machine learning solutions are delivered by solid engineers who glue together solid commodity components. Quoting Google’s Rules of Machine Learning:
To make great products: do machine learning like the great engineer you are, not like the great machine learning expert you aren’t.
Most of the problems you will face are, in fact, engineering problems. Even with all the resources of a great machine learning expert, most of the gains come from great features, not great machine learning algorithms. So, the basic approach is:
- Make sure your pipeline is solid end to end.
- Start with a reasonable objective.
- Add common-sense features in a simple way.
- Make sure that your pipeline stays solid.
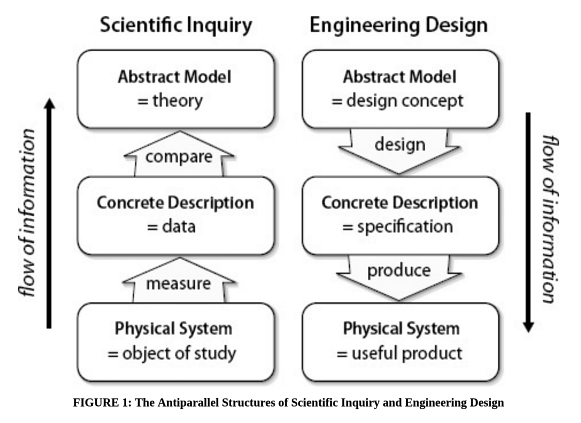
Many problems in data “science” are actually engineering problems – described best by the flow on the right (source)
Some of my first jobs as a data scientist in industry involved building recommender systems. With recommender systems, much of the work is on the system around the recommendation algorithm. That is, building a recommender system was always mostly an engineering problem. However, these days we have services like AWS Personalize, which does most of the heavy lifting around recommendation. This makes the deployment of recommender systems a pure engineering problem. Like many other problems, recommender systems have been commodified.
I have not done much with deep learning, but there the general trend is even more apparent: Useful innovations quickly turn into tools. Examples include library evolution from Theano to TensorFlow, and commodified prediction services from companies like Google, Amazon, and Microsoft. If you want to use a deep learning service in your application, you probably don’t need a data scientist or even a machine learning engineer. A solid software engineer who can pick the right tools should be enough.
How to remain relevant?
So where does this leave us? It seems to be a more general phenomenon. Essentially every problem that requires specialised knowledge and is valuable ends up attracting repeatable solutions that obviate the need for deep thinking and manual work. These solutions are software commodities. Deploying them is a matter of writing some glue code and fitting them into the overall system – an engineering problem. Implementing data science components to compete with commodities may be interesting and fun, but it’s usually a waste of time when there’s a generic solution that is good enough.
As an individual data scientist, what can you do when your speciality becomes a software commodity? I see a few options:
- Embrace the engineering angle. Become good (or better) at engineering solutions. Be pragmatic. Do what it takes to get the job done. This is probably easier for data scientists like me, who have an engineering background, than for more research/analysis-oriented data scientists. Such data scientists sometimes sneer at engineering work, claiming it’s “fake” data science. Fake or not, solid engineering tools can easily make stubborn data scientists obsolete.
- Keep building custom solutions even when viable commodities exist. While this may be more fun for the individual, I believe it isn’t a sustainable approach. The cost of building and maintaining custom solutions will typically be higher than the cost of commodity solutions. Insisting on custom solutions seems like a recipe for becoming irrelevant.
- Keep adapting and moving to non-commodity areas. Some things are easier to automate than others. For example, building a machine learning pipeline when the problem is well-defined is relatively easy, but deciding what features to create typically requires some domain expertise. In addition, new research keeps coming out in areas that are less hot than machine learning. One such area is causal inference, where there are still solutions that are yet to be commodified.
- Move to the cutting edge. If you want to research novel methods, a “standard” data scientist position may not be for you. Many industry positions are focused on applying proven solutions to a specific organisation. If that doesn’t sound like fun, you’re better off moving to academia or joining a commercial research group.
Are there any other options I don’t see? Let me know in the comments!
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.
John Chew
2020-01-11 09:35:15
Boris Gorelik
2020-01-12 20:08:29
Yanir Seroussi
2020-01-12 21:20:19
antonisbtr
2020-01-16 18:09:52
Hi Yanir!
The post really reasonated with me. I find more and more that I do engineering during my day than science.
I believe the data engineering part, including cloud and full stack development skills, will prove to be the skills that keep you relevant in industry. If you combine these with knowledge on which techniques to use regarding data science and machine learning, then you can be unstoppable.
Otherwise, as you said, it’s better to stay in academia.
Best, Antonios
Audrey D
2021-07-14 18:24:40
Hi Yanir,
I am glad I found your post. I am switching careers and want to work with data for social good. I learned data analysis, and am thinking of explore machine learning, see if that’s something for me. Being an engineer (not tech related), I would definitely be content with your option 1, where I understand what’s going on behind the scenes but don’t get into research and maths.
Interesting to know what the trend is in the field.