
The world was a different place in 2012. I had just finished my PhD, and I wasn’t sure what my title should be. My formal academic transcript said that I specialised in artificial intelligence, but back then it seemed silly to call myself an AI Expert. As I was interested in startups, I became the first employee of Giveable, and my title was Data Scientist. This was the year Harvard Business Review declared data scientist to be the sexiest job of the 21st century, so it suited me just fine. I got to do work I found interesting while reaping the benefits of being in an over-hyped profession.
As data science was a new term, I attempted to decipher its evolving meaning. In 2014, I liked the definition by Josh Wills, who saw it as the intersection of software engineering and statistics. By 2018, I came to see it as the union of many fields, with practitioners who support and drive decisions by employing descriptive analytics, predictive models, and causal inference. In 2020, I reflected on the trend of software commodities displacing interesting data science work. Now, I look back and wonder: Was data science a failure mode of software engineering? That is, did many data science projects repeat classic software engineering mistakes (especially in the early days)?
Breaking Betteridge’s law of headlines, my answer to these questions is yes. I believe that many instances of data science projects exhibited classic software engineering mistakes, especially in the 2010s. Things appear to be getting better, though. The emergence of professions like data engineering, machine learning engineering, and analytics engineering represents a move away from getting data scientists to fail at software engineering – simply because they need to do less of it. But this isn’t the case everywhere, as data maturity varies across organisations.
Failure mode examples
For a data science project to exhibit a failure mode of software engineering, it needs to: (1) have working software as one of its outcomes; and (2) fail in a way that software engineering projects are known to fail.
Not all data science projects meet my first criterion. Some projects end with a one-off report as their outcome, which is fine if that’s the project’s goal. However, many data science projects aim to deliver software systems that need to operate continuously and reliably. Quoting one of the principles behind the agile manifesto, for projects of the latter type, working software is the primary measure of progress. My sense is that such projects were driving the data science hype, e.g., a personalisation system that automatically increases revenue is both more exciting and more valuable than a one-off report.
For my second criterion, I’ll discuss some classic software engineering mistakes and how they manifest in data science projects. These come from a list compiled by Steve McConnell in 1996 and updated in 2008. While some mistakes have become less common, many are still repeated to this day. As Jeff Atwood noted in 2007, “classic mistakes are classic because they’re so seductive.” The updated list contains 42 mistakes, so I’ll highlight five I find especially pertinent: unrealistic expectations, heroics, research-oriented development, silver-bullet syndrome, and lack of automated source-code control.
(M1) Unrealistic expectations. This mistake had the highest exposure index in McConnell’s 2008 report, meaning it’s both frequent and severe. I don’t have solid data on the occurrence of this mistake in data science projects, but unrealistic expectations go hand in hand with an over-hyped field. This is exemplified by the Gartner hype cycle, where technologies hit a peak of inflated expectations followed by a trough of disillusionment. While the general validity of the hype cycle model is questionable, I’ve experienced enough instances of unrealistic expectations and heard enough stories to believe that many data science projects have not escaped this classic mistake.
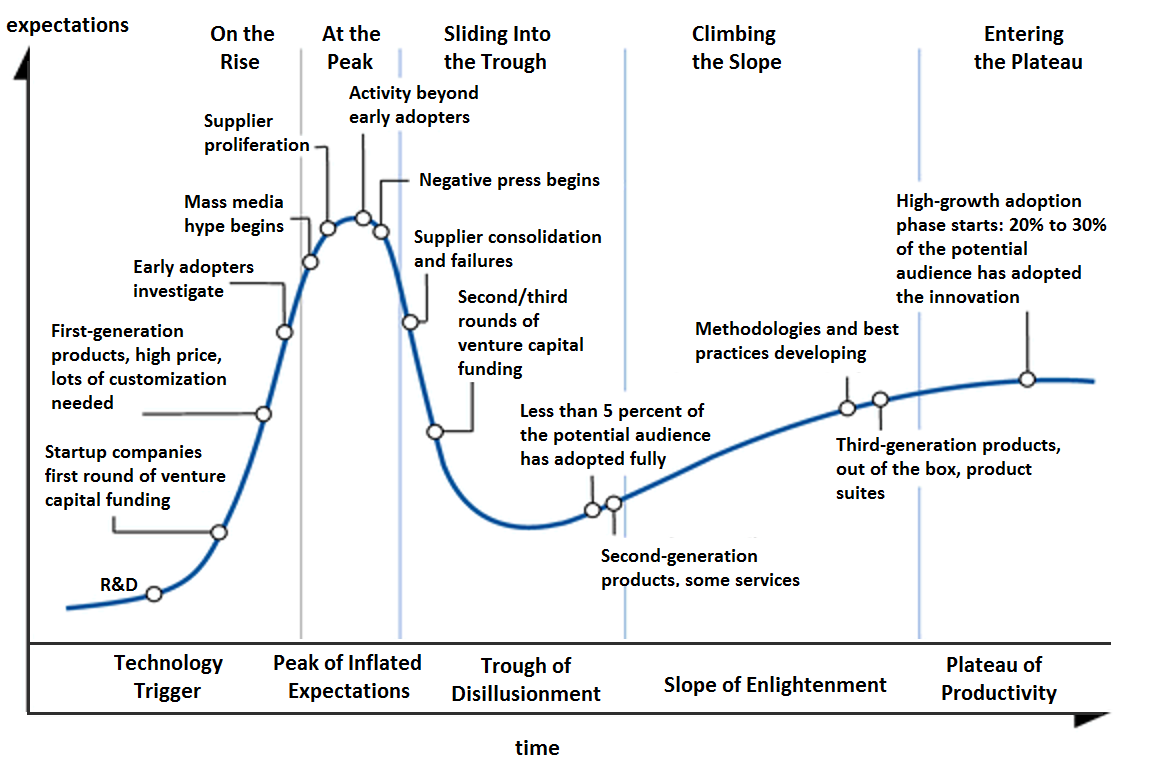
Gartner hype cycle. Source: Olga Tarkovskiy, CC BY-SA 3.0, via Wikimedia Commons.
(M2) Heroics. This classic mistake is probably best exemplified by the labelling of data scientist as the sexiest job of the 21st century. Yes, it was just a Harvard Business Review article, but with almost 2,000 scholarly citations and numerous other mentions, it’s beyond doubt that it had helped paint a picture of data scientists as heroes who “understand how to fish out answers to important business questions from today’s tsunami of unstructured information”. More careful reading of the original article reveals that the authors referred to data scientist as “the hot job of the decade” (emphasis mine). Indeed, the same authors published a follow-up article in 2022 that implicitly follows Betteridge’s law of headlines: Is Data Scientist Still the Sexiest Job of the 21st Century? The 2022 article notes that “businesses now need to create and oversee diverse data science teams rather than searching for data scientist unicorns”, or in more detail:
The data science role is also now supplemented with a variety of other jobs. The assumption in 2012 was that data scientists could do all required tasks in a data science application — from conceptualizing the use case, to interfacing with business and technology stakeholders, to developing the algorithm and deploying it into production. Now, however, there has been a proliferation of related jobs to handle many of those tasks, including machine learning engineer, data engineer, AI specialist, analytics and AI translators, and data oriented product managers. LinkedIn reported some of these jobs as being more popular than data scientists in its “Jobs on the Rise” reports for 2021 and 2022 for the U.S.
While I have my doubts about AI specialist ever becoming a well-defined profession, it seems like the days of “sexy” data science heroes are thankfully behind us.
(M3) Research-oriented development. This classic mistake is possibly one of the top reasons so many data science projects had failed to make it to production. Leaning towards research was probably due to many early data scientists coming from academia (or having an academic fetish, as noted by one Reddit commenter). However, there’s a fine distinction to draw between research and experimentation. Research aims to expand the frontiers of knowledge, which is an expensive, high-risk activity that should be avoided by most organisations. By contrast, experimentation aims to uncover truths and opportunities within a limited area, e.g., optimising landing pages for a specific product. In many business domains, rigorous experimentation requires a robust software platform. Having worked on such a platform myself, I consider this type of experimentation to be a data science success story, even though some people see A/B testing and causal inference as less “sexy” than machine learning.
(M4) Silver-bullet syndrome. McConnell’s description of this mistake should be familiar to anyone who’s been in tech for long enough:
On some projects, there is an over reliance on the advertised benefits of previously unused technologies, tools, or 3rd party applications and too little information about how well they would do in the current development environment. When project teams latch onto a single new methodology or new technology and expect it to solve their cost, schedule, or quality problems, they are inevitably disappointed.
The silver bullet may be data science, or it may be AI, large language models, big data, or blockchain. As long as humans are running things, it’s unlikely we’d run out of silver bullets. While many have warned that data science isn’t a silver bullet (e.g., see my early posts on data’s hierarchy of needs and avoiding premature hiring of data scientists), people still fell for it. And people still fall for the latest shiny thing. I’m not immune either, e.g., I still find ChatGPT to be transformative and believe that AI will keep changing our world. But I can’t put a timeline on global transformations, and I doubt that a single technology would solve all the world’s problems.

Will big data ever make a resurgence as a silver bullet?
(M5) Lack of automated source-code control. While McConnell’s 2008 report found this to be a low-frequency mistake, data science may have helped resuscitate it. This is due to multiple factors:
- Using notebooks for development and experimentation. I use notebooks myself – they are popular for a reason. However, they don’t play well with source control systems without additional tooling. For example, it’s hard to collaborate on notebooks as people do on plain code – just try merging notebook changes from multiple authors for a bit of fun.
- Many data scientists came from fields where source control wasn’t common. This is probably decreasing now with Git being the standard source control system, but it wasn’t the case about a decade ago.
- Data transformations don’t always live under source control. For example, analytics flows might be buried in stored procedures or database views, or worse – copied around by analysts. Again, this is changing thanks to a growing awareness and the rise of tools like dbt, but not everyone has adopted the modern data stack yet.
Related to a lack of source-code control is a lack of control over model versioning and data lineage, as it takes some experience to develop an appreciation of the need for versioning and reproducibility. Still, it’s easy to end up with a big mess even with an awareness of these issues and the best intentions. It’s hard to control everything.
Learning from history while moving forward
Data science is maturing. We’ve gone from a “sexy” field to people calling themselves “recovering data scientists”, saying goodbye to the field, and declaring that “there will be no data science job titles by 2029”. Anecdotally, it seems to me like data science is becoming less of a failure mode of software engineering – perhaps because data scientists are no longer expected to single-handedly ship complex software systems.
Personally, I still struggle with giving a concise title to what I do, just like in 2012. Data scientist has become a loaded term – some see data science as a cost centre that fails to deliver tangible results. As I’ve never stopped doing software engineering, I try to emphasise it by saying that I’m a full-stack data scientist and software engineer. This is a bit of a mouthful, and full-stack is also a loaded term, but it seems apt because I’ve shipped production code that ranges from old-school C on pre-Android phones through data pipelines to web applications. My main concern these days is putting my skills to good use, especially within climate tech and related areas. But as I’m freelancing, I went with Data & AI Consultant as my LinkedIn job title – maybe my PhD specialisation in AI wasn’t so silly after all…?
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.