
Recently, I’ve been thinking on startup data problems to clarify where I can help potential clients. With over a decade in the data / AI / ML world, I’ve seen new hype waves and job titles appear almost every year. While for insiders this may seem natural, outsiders aren’t fully aware of the differences between the types of data professionals and the problems they solve.
One way I classify startup data problems is with the question: Do you need MLOps?
- If the answer is Yes, then it’s an ML-centric startup. Machine learning is core to the product, so effectively training, deploying, and maintaining ML models (i.e., doing MLOps) is crucial. Such startups should have strong ML and data capabilities in the founding team. Their success depends on it.
- If the answer is No, then it’s a non-ML startup. Such startups may occasionally build a one-off model, but they won’t be dealing with MLOps early on. Unless they’re building a data-intensive product,1 non-ML startups should hold off on hiring data people until they start hitting product-market fit and scaling their marketing. They can afford to build their data capabilities incrementally with a minimum viable data stack, and follow well-trodden paths of supporting decisions with data.
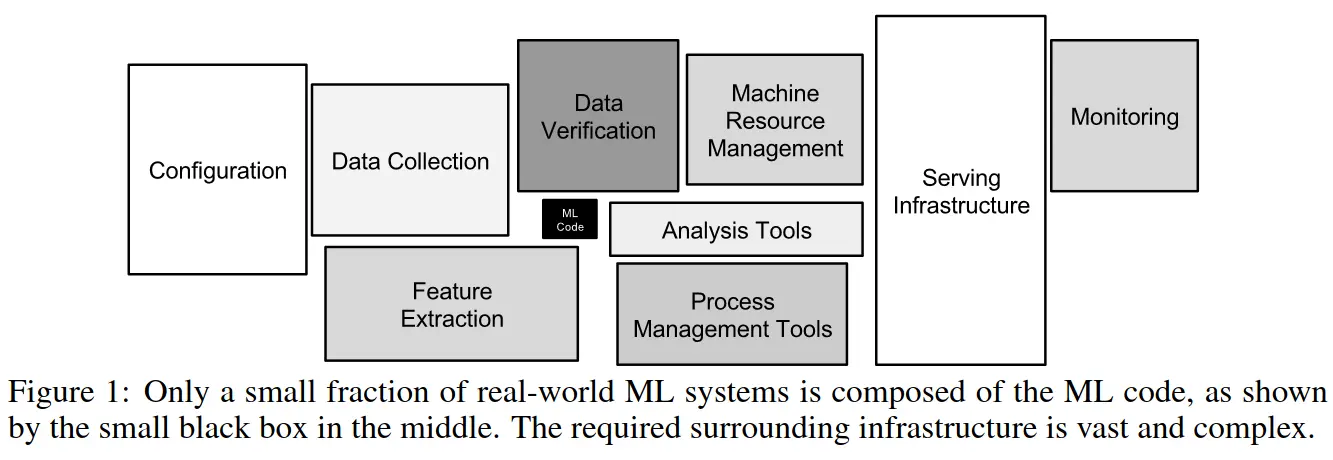
Somewhat confusingly, there’s an overlap between the skills required for ML-centric startups and those required from data people in non-ML startups. This is because much of ML is data work. This is reflected by the following ML system diagram, where the Data Collection and Data Verification boxes are much larger than the ML Code box. Additionally, the Analysis Tools and Monitoring boxes also require data skills, as defining metrics is one of the hardest problems of data science.
Side note: LLMs and black-box APIs. If LLMs are a core part of the product, I still consider it to be an ML-centric startup. I’m not sure if the term LLMOps will catch on, but it has a lot in common with MLOps. Likewise, using LLMs for retrieval-augmented generation is similar to building recommender systems, i.e., ML-centric. The same reasoning applies to black-box ML APIs: If they form a core part of the product, it’s an ML-centric startup because you need to think of data and metrics early on.
Examples from my past
My employment history includes work with both ML-centric and non-ML startups. These examples may help clarify the differences between the two startup types:
- ML-centric startup: After my PhD, I was a founding data scientist with a startup called Giveable, where the product was a recommender system for gifts. Giveable disbanded, but I took the codebase to Next Commerce – a company that had a few products in the e-commerce space. There, I led the team that turned Giveable into Hynt – a recommender system as a service.
- Non-ML startup: I was the first data hire at Car Next Door (now Uber Carshare). Despite my fancy Head of Data Science title (data science was still hyped up at the time), I did a lot of engineering work – including data & analytics engineering. I also built ML-ish models of customer lifetime value, but it was too early in the company’s life for anything too sophisticated on the ML front.
- ML work at a non-ML scaleup: After Car Next Door, I spent 4.5 years at Automattic. The company’s headcount grew about 3-4 times in my time there (from about 500 employees). This growth included investment in data and ML: One major project I worked on was ML pipelines to improve marketing performance (e.g., automatically target customers that are most likely to upgrade as a result of a well-timed email). However, I was also involved in data-intensive projects that didn’t include ML.
- ML-centric product with a non-ML startup: After Automattic, I joined Orkestra to help them build a new product that had ML at its core. However, the company’s main product wasn’t an ML product, and I left on good terms when they pivoted to focus on their main offering.
With Giveable/Hynt and Orkestra, attempting ML product development without thinking of MLOps wasn’t going to work. With Car Next Door and Automattic, the company’s success never depended on MLOps, so an incremental approach to using data and ML was viable.
Closing thoughts
While both ML-centric and non-ML startups face data problems, the centrality of data varies between the two. Trying to run an ML-centric startup without a solid grasp of MLOps and data engineering practices is a recipe for failure, while non-ML startups can get away with less-than-ideal data practices for a long time.
Personally, I’m always on the lookout for better ways of explaining these differences and coming up with accessible terminology to help founders who are navigating the space. ML-centric and non-ML will do for now, but other suggestions are welcome!
This is a fine example of an advantage of writing publicly. The initial version of this post didn’t include the qualification of “unless they’re building a data-intensive product” – I realised it was missing the following day. Perhaps a better classification is data-centric versus data-supported, but I’ll leave that to a future post. ↩︎
Public comments are closed, but I love hearing from readers. Feel free to contact me with your thoughts.